kubeadm部署k8s集群教程
本文详细介绍了使用kubeadm部署Kubernetes集群的完整流程,包括准备工作、Docker安装、kubelet/kubeadm/kubectl安装、cri-dockerd安装、集群部署(master节点初始化与worker节点加入)、Calico网络扩展安装以及集群状态验证等步骤。
准备工作
准备3台虚拟机
| 操作系统 | HostName | IP | 内存 | CPU | 磁盘 | 角色 |
|---|---|---|---|---|---|---|
| Debian12 | k8smaster1 | 172.16.126.130 | 2G | 2C | 50G | master |
| Debian12 | k8sworker1 | 172.16.126.131 | 2G | 2C | 50G | worker |
| Debian12 | k8sworker2 | 172.16.126.132 | 2G | 2C | 50G | worker |
注意⚠️: 以下操作,3台机器上都需要执行。
设置静态IP
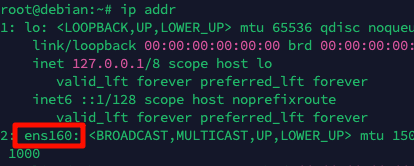
查看当前ip信息
ip addr
记下网卡名称,一般是第二个,例如我的是ens160
设置静态IP地址
vim /etc/network/interfaces
# lo改为ens160
auto ens160
# 修改为static
iface ens160 inet static
# 指定静态ip,这里注意3台机器的ip分别为172.16.126.130,172.16.126.131,172.16.126.132
address 172.16.126.130
netmask 255.255.255.0
# 如果是vmware,一般网关最后一位是2,你也可以查询您的vmware的网关设置
gateway 172.16.126.2
重启网络
systemctl restart networking
修改主机名
在3台主机上分别执行以下命令
hostnamectl hostname k8smaster1
hostnamectl hostname k8sworker1
hostnamectl hostname k8sworker2
修改hosts
vim /etc/hosts
172.16.126.130 k8smaster1
172.16.126.131 k8sworker1
172.16.126.132 k8sworker2
关闭swap
查看swap
# 结果显示空白则说明swap已经关闭
swapon --show
临时关闭swap(服务器重启会失效)
swapoff -a
永久关闭,即注释掉/etc/fstab中的swap那一行
sed -i 's/.*swap.*/#&/' /etc/fstab
如果修改fstab并且重启系统后发现swap还没有关闭,则还需要执行以下操作
systemctl list-unit-files --type=swap
# 找到swap的unit文件,例如dev-nvme0n1p3.swap
systemctl mask dev-nvme0n1p3.swap
重启系统
关闭防火墙
iptables -F
systemctl stop iptables nftables
systemctl disable iptables nftables
ufw disable
启用 IPv4 数据包转发
手动加载模块(重启后失效)
modprobe br_netfilter
设置启动自动加载
cat << EOF | tee /etc/modules-load.d/br_netfilter.conf
br_netfilter
EOF
查看模块是否加载成功
lsmod | grep "br_netfilter"
设置ipv4转发
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
使生效
sysctl --system
配置时间同步
apt install ntpdate -y
ntpdate ntp.aliyun.com
添加定时任务
crontab -e
# 添加内容,并保存
0 0 * * * ntpdate ntp.aliyun.com
立即生效
service cron restart
安装docker
安装
设置
安装后设置 Post-installation steps | Docker Docs
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
sudo systemctl enable docker.service
sudo systemctl enable containerd.service
配置驱动和镜像加速
修改docker 文件驱动为 systemd kubelet 默认使用 systemd,两者必须一致才可以
cat << EOF > /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://ghcr-pull.ygxz.in"
]
}
EOF
重启docker
systemctl daemon-reload
systemctl restart docker
systemctl status docker
安装 kubelet、kubeadm 和 kubectl
文档: 安装 kubeadm、kubelet 和 kubectl | Kubernetes
添加k8s apt官方仓库
sudo apt-get update
# apt-transport-https 可能是一个虚拟包(dummy package);如果是的话,你可以跳过安装这个包
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
# 如果 `/etc/apt/keyrings` 目录不存在,则应在 curl 命令之前创建它,请阅读下面的注释。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
在低于 Debian 12 和 Ubuntu 22.04 的发行版本中,`/etc/apt/keyrings` 默认不存在。 应在 curl 命令之前创建它
# 此操作会覆盖 /etc/apt/sources.list.d/kubernetes.list 中现存的所有配置。
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
安装 kubelet、kubeadm 和 kubectl,并锁定其版本,不让其自动更新
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
开机自动启动
systemctl enable kubelet
查询版本
kubeadm version
得到GitVersion:"v1.31.0"
安装cri-dockerd
查询当前kubernetes所需要的pause镜像的版本
kubeadm config images list --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --kubernetes-version=v1.31.0| grep pause
输出结果为: registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
从此得知k8s 1.31.0版本使用的pause版本为3.10,下面配置cri-dockerd的启动参数要用到
安装cri-dockerd
官方文档https://mirantis.github.io/cri-dockerd/usage/install/
下载地址 https://github.com/Mirantis/cri-dockerd/releases
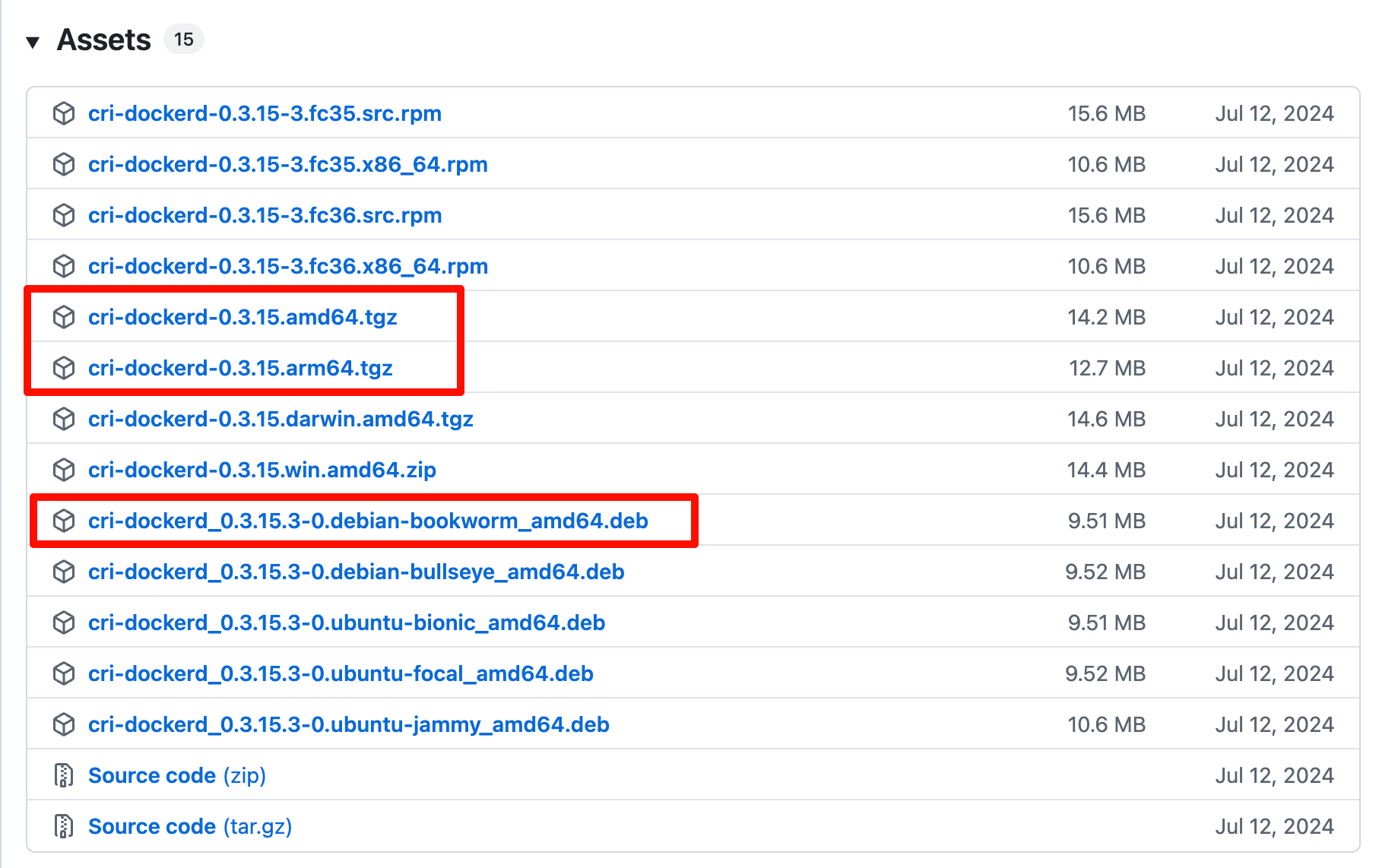
注: 这里分两种情况,如果您的系统为amd64架构,则可以使用deb包安装,如果是arm64架构使用二进制文件方式安装
方式一、deb包方式安装
下载
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.15/cri-dockerd_0.3.15.3-0.debian-bookworm_amd64.deb
安装
dpkg -i cri-dockerd_0.3.15.3-0.debian-bookworm_amd64.deb
修改配置文件
vim /etc/systemd/system/multi-user.target.wants/cri-docker.service
修改其中的ExecStart,注意pause的版本要和k8s的版本一致
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
方式二、二进制文件方式安装
下载
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.15/cri-dockerd-0.3.15.arm64.tgz
解压
tar zxvf cri-dockerd-0.3.15.arm64.tgz
安装
install -o root -g root -m 0755 cri-dockerd/cri-dockerd /usr/local/bin/cri-dockerd
添加配置文件
vim /etc/systemd/system/cri-docker.service
内容为:
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
# 1.修改cri-dockerd的路径,2.添加pod-infra-container-image,注意pause的版本要跟k8s的版本一致
ExecStart=/usr/local/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
添加配置文件:
vim /etc/systemd/system/cri-docker.socket
内容为:
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
这两个配置文件的下载地址为: https://github.com/Mirantis/cri-dockerd/tree/master/packaging/systemd
重启cri-dockerd
systemctl daemon-reload
systemctl enable --now cri-docker.socket
systemctl restart cri-docker
systemctl status cri-docker
部署k8s
初始化k8smaster主节点
注意⚠️: 初始化k8smaster主节点这一步骤只需要在master机器上执行
通过配置文件方式初始化 k8s
先打印默认配置文件到yaml文件中,再修改其中内容
kubeadm config print init-defaults > kubeadm-config.yaml
编辑配置文件,具体需要修改的地方我都加了#号说明
vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
# token 24小时过期
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
# 修改为当前主机ip,例如我的是172.16.126.130
advertiseAddress: 172.16.126.130
bindPort: 6443
nodeRegistration:
# 因为我使用的是cri-dockerd,因此修改此处
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
imagePullSerial: true
# 节点名修改为当前主机名
name: k8smaster1
taints: null
timeouts:
controlPlaneComponentHealthCheck: 4m0s
discovery: 5m0s
etcdAPICall: 2m0s
kubeletHealthCheck: 4m0s
kubernetesAPICall: 1m0s
tlsBootstrap: 5m0s
upgradeManifests: 5m0s
---
apiServer: {}
apiVersion: kubeadm.k8s.io/v1beta4
# 配置CA certificate有效期,默认是10年,下面改为100年
caCertificateValidityPeriod: 876000h0m0s
# 配置non-CA certificate有效期,默认1年,下面改为100年
certificateValidityPeriod: 876000h0m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
encryptionAlgorithm: RSA-2048
etcd:
local:
dataDir: /var/lib/etcd
# 修改拉取镜像的仓库为阿里云,因为默认的仓库在国外,国内环境下载不了
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
# 指定k8s版本
kubernetesVersion: 1.31.0
networking:
dnsDomain: cluster.local
# service网段保持默认即可
serviceSubnet: 10.96.0.0/12
# 添加下面一行,指定Pod所使用的子网,在下面配置网络扩展时需用到
podSubnet: 10.244.0.0/16
proxy: {}
scheduler: {}
执行初始化命令:
kubeadm init --config kubeadm-config.yaml --v=9
或
kubeadm init --config kubeadm-config.yaml --upload-certs --v=9
期间会进行各种检查和下载镜像,等待执行完成
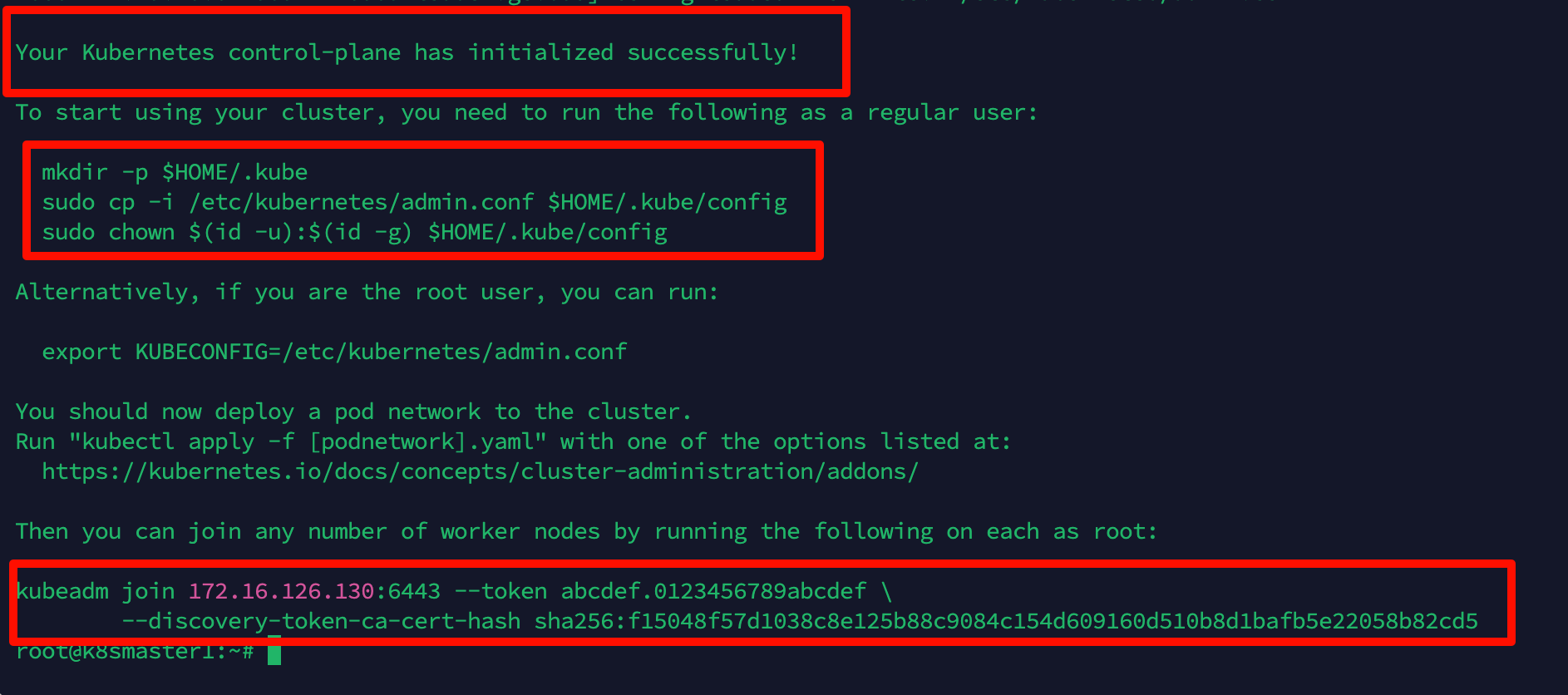
按安装说明执行以下命令, 复制配置文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
复制kubeadm join命令,在worker节点执行此命令即可加入集群
如果你不小心忘记复制join命令,也可以通过create命令创建新的token来扩容 k8s 集群-添加工作节点:
kubeadm token create --print-join-command
走到这一步,master节点的初始化工作都已完成。
加入worker节点
注意⚠️: 加入worker节点这一步骤只需要在worker机器上执行
在worker节点执行上面复制的join命令:
kubeadm join 172.16.126.130:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:f15048f57d1038c8e125b88c9084c1609160d510b8d1bafb5e22058b82cd5 --cri-socket unix:///var/run/cri-dockerd.sock
注意⚠️: 因为使用的容器运行时是cri-dockerd,所以在worker节点执行join命令时,需要添加参数--cri-socket unix:///var/run/cri-dockerd.sock
验证: 在master节点中执行以下命令:
root@k8smaster1:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster1 NotReady control-plane 14m v1.31.0
k8sworker1 NotReady <none> 4m1s v1.31.0
k8sworker2 NotReady <none> 4m12s v1.31.0
可以看到k8smaster1是control-plane控制平面,两个worker节点的 ROLES 为 none, 表示这两个节点是工作节点。我们也可以通过以下命令将其改为worker,不改也没关系.
kubectl label node k8sworker1 node-role.kubernetes.io/worker=worker
kubectl label node k8sworker2 node-role.kubernetes.io/worker=worker
另外,上面status都是 NotReady 状态,是因为我们还没有安装网络扩展
安装网络扩展
注意⚠️: 安装网络扩展这一步骤只需要在master机器上执行命令
参考文档: https://kubernetes.io/zh-cn/docs/concepts/cluster-administration/addons/
安装网络扩展Calico
安装 kubernetes 网络组件-Calico
官方文档: Quickstart for Calico on Kubernetes | Calico Documentation (tigera.io) 注: 只需执行文档中step2即可
先下载两个yaml文件
wget -O tigera-operator.yaml https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/tigera-operator.yaml
wget -O custom-resources.yaml https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/custom-resources.yaml
修改custom-resources.yaml中的cidr: 10.244.0.0/16, 其中10.244.0.0/16是上面kubeadm init步骤中配置文件中指定的参数podSubnet: 10.244.0.0/16
# This section includes base Calico installation configuration.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
# 修改此处为与kube-config.yaml中的podSubnet的值一致
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
# This section configures the Calico API server.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
创建calico网络扩展
kubectl create -f tigera-operator.yaml
kubectl create -f custom-resources.yaml
验证Calico网络扩展是否安装成功
查看组件是否都启动成功
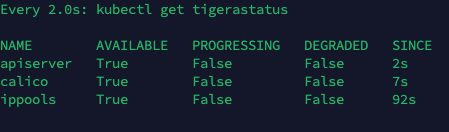
以下命令监控部署是否成功,如果顺利,几分钟后,所有 Calico 组件在 AVAILABLE 列中显示 True,这个过程根据网络情况,可能需要一些时间
watch kubectl get tigerastatus
以下命令确认pod是否运行成功,全部running即启动成功
watch kubectl get pods -n calico-system
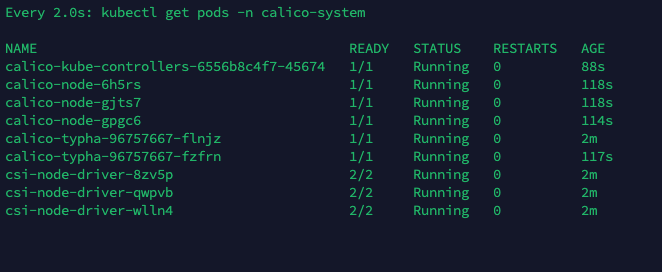
如果长时间没ready,可以尝试以下命令describe po,查看为什么没ready
kubectl describe -n calico-system po xxx
以上成功后,再次查询节点状态
kubectl get nodes
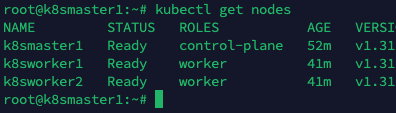
STATUS 状态是 Ready,说明 k8s 集群正常运行了
测试在 k8s 创建 pod 是否可以正常访问网络
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
ping www.baidu.com
通过上面可以看到能访问网络,说明 calico 网络扩展已经被正常安装了
测试 coredns 是否正常
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
nslookup kubernetes.default.svc.cluster.local
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default.svc.cluster.local
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
10.96.0.10 就是我们 coreDNS 的 clusterIP,说明 coreDNS 配置好了。
解析内部 Service 的名称,是通过 coreDNS 去解析的
到此, 1主2从的k8s集群已经部署成功
局限性
此处创建的集群具有单个控制平面节点,运行单个 etcd 数据库。 这意味着如果控制平面节点发生故障,你的集群可能会丢失数据并且可能需要从头开始重新创建。
解决方法:
- 定期备份 etcd。 kubeadm 配置的 etcd 数据目录位于控制平面节点上的 /var/lib/etcd 中。
- 使用多个控制平面节点。 你可以阅读可选的高可用性拓扑选择集群拓扑提供的 高可用性。